A 20-minute introduction to SQL¶
A quick overview of SQL: History, Concepts, and Syntax.
History¶
SQL == Structured Query Language
- First invented in the early 1970s at IBM
- Based on Relational Algebra and Tuple Relational Calculus
- Used to get at data stored in their System-R database management system
- Picked up by Relational Software (now Oracle) in the late 1970s
- Oracle V2, the first commercial Relational Database released in 1979
- IBM followed with System/38, SQL/DS and DB2 between 1979 and 1983
source: http://en.wikipedia.org/wiki/SQL
SQL, and Relational Database Management Systems (RDBMS) have been the de-facto standard for data persistence for 30+ years.
Currently, there are more than 100 RDBMS available, both proprietary and open-source.
Most, if not all, include some implementation of SQL as their query language.
source: http://en.wikipedia.org/wiki/List_of_relational_database_management_systems
Big Players¶
There are a number of RDBMS that you will run into regularly:
Commercial / Proprietary
- MS SQL Server
- Oracle
- MySQL Enterprise (Oracle)
Open Source
- PostgreSQL
- MariaDB (MySQL community)
- SQLite
SQL Concepts¶
The core construct in SQL is a table
A table consists of rows (also called records) and columns
Each row/record represents a single item.
Each column represents a data point.
Most tables will have one column which is considered the primary key.
This value will uniquely identify a single row out of all the rows in the table.
For example, here is an example table which represents people in a system:
| id | username | first_name | last_name |
|---|---|---|---|
| 1 | wont_u_b | Fred | Rogers |
| 4 | neuroman | William | Gibson |
| 5 | race | Roger | Bannon |
| 6 | harrywho | Harry | Houdini |
| 7 | whitequeen | Emma | Frost |
| 8 | shadowcat | Kitty | Pryde |
Relations¶
You can model things using tables like this. Adding columns for all sorts of different data points.
But what happens when not all of the items in a table share the same data points?
Or what if some of the items need to have more than one of a particular data point?
Leaving columns empty in a row wastes memory and slows down querying. Use relations to solve these types of problems.
There are three basic types of relationships:
- One-to-one relationships
- Best used to represent aspects of an item which are not core to it. Like user (id, password) -> user_profile (preferences, name, address)
- Many-to-one relationships
- Used to represent relationships of ownership or belonging. Like product -> manufacturer or book -> author
- Many-to-many relationships
- Used to represent associations or membership. Like users -> groups or items -> orders
SQL Relations - ∞ -> 1¶
Many-to-one relationships are modelled using Foreign Keys
The many table has a column which holds the primary key of the row from the one table:
For example, consider the relationship of books to author:
People:
| id | username | first_name | last_name |
|---|---|---|---|
| 4 | neuroman | William | Gibson |
| 6 | harrywho | Harry | Houdini |
Books:
| id | title | author |
|---|---|---|
| 1 | Miracle Mongers and their Methods | 6 |
| 2 | The Right Way to Do Wrong | 6 |
| 3 | Pattern Recognition | 4 |
SQL Relations - 1 -> 1¶
One-to-one relationships are really just a special case of Many-to-one, and are also modelled with Foreign Keys
In this case, the column on the related table which holds the primary key of the target table has an additional unique constraint, so that only one related record can exist
The classic purpose is for data that doesn’t need to be accessed often, and is unique per record
As an example of this, consider a databse of birth records:
People:
| id | username | first_name | last_name |
|---|---|---|---|
| 1 | wont_u_b | Fred | Rogers |
| 4 | neuroman | William | Gibson |
| 5 | race | Roger | Bannon |
Birth Records:
| id | person | date | place |
|---|---|---|---|
| 1 | 1 | March 20, 1928 | Latrobe, PA |
| 2 | 4 | March 17, 1948 | Conway, SC |
| 3 | 5 | April 1, 1954 | Wilmette, IL |
SQL Relations - ∞ -> ∞¶
Many-to-many relations are a bit trickier.
You can’t have a multi-valued field, so there’s no way to define a foreign key-like construct that would work
Instead, this relationship is modelled using a join table, which has two foreign key fields, one for each side of the relation.
Beyond these two, other columns can add data points describing the qualities of the relationship itself.
For this example, consider a database modelling the membership of people in groups or organizations:
People:
| id | username | first_name | last_name |
|---|---|---|---|
| 7 | whitequeen | Emma | Frost |
| 8 | shadowcat | Kitty | Pryde |
Groups:
| id | name |
|---|---|
| 1 | Hellfire Club |
| 2 | X-Men |
Membership:
| id | person | group | active |
|---|---|---|---|
| 1 | 7 | 1 | False |
| 2 | 7 | 2 | True |
| 3 | 8 | 2 | True |
SQL Syntax¶
The syntax of SQL can be broken into four basic constructs:
- Statements are discreet units that perform some action, like inserting records or querying
- Clauses are sub-units of statements which indicate some action or condition
- Expressions are elements that produce values, either unitary or as tables themselves
- Predicates are conditionals which produce some boolean or three-valued truth value
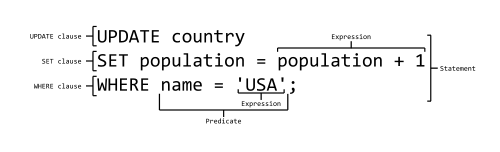
image: CC-BY-SA by Ferdna http://en.wikipedia.org/wiki/File:SQL_ANATOMY_wiki.svg
{kind=link}
Syntactic Subsets¶
SQL statements can be thought of as belonging to one of several subsets:
- Data Definition
- Statements in this subset concern the structure of the database itself:
CREATE TABLE "jos_groups" (
"group_id" character varying(32) NOT NULL,
"name" character varying(255) NOT NULL,
"description" text NOT NULL
)
- Data Manipulation
- Statements in this subset concern the altering of data within the database:
UPDATE people
SET first_name='Bill'
WHERE id=4;
- Data Query
- Statements in this subset concern the retrieval of data from within the database:
SELECT user_id, COUNT(*) c
FROM (SELECT setting_value AS interests, user_id
FROM user_settings
WHERE setting_name = 'interests') raw_uid
GROUP BY user_id HAVING c > 1;
Statements from within each of these subsets are said to belong to a particular layer.
- DDL for Data Definition statements
- DML for Data Manipulation statements
- DQL for Data Query statements